摘要:
帶你深入了解TensorFlow框架下的LSTM時間序列預(yù)測
現(xiàn)實生活中����,我們經(jīng)常會遇到各式各樣的時間序列預(yù)測場景,比如�����、股票和黃金價格的預(yù)測商品銷量的預(yù)測等等���。TensorFlowTime Series(以下簡稱TFTS)專門設(shè)計了一套針對時間序列預(yù)測問題的API����,利用其提供的LSTM模型���,可以實現(xiàn)在TensorFlow中快速搭建高性能時間序列預(yù)測系統(tǒng)����。LSTM具有優(yōu)于傳統(tǒng)神經(jīng)網(wǎng)絡(luò)框架的優(yōu)勢����。雖然用TensorFlow與LSTM結(jié)合來做時間序列預(yù)測是一個很舊的話題,然而卻一直沒有得到比較好的解決或分析��。本文結(jié)合實例代碼帶你從零開始輕松搭建TensorFlow深度學(xué)習(xí)框架下LSTM高性能時間序列預(yù)測系統(tǒng)。
所謂的時間序列預(yù)測是指在某些未來時間點預(yù)測數(shù)據(jù)的值的多少�。時間序列預(yù)測主要基于連續(xù)性原理。在現(xiàn)實生活中�,大多數(shù)事物的基本發(fā)展趨勢將在未來繼續(xù),其產(chǎn)生的數(shù)據(jù)也將滿足時間序列的連續(xù)性原則����。所以在實際應(yīng)用中,時間序列預(yù)測具有較強的實用性��。預(yù)測效果與預(yù)測模型的選擇密不可分��。
TensorFlow是一種基于圖的計算框架��。正如TensorFlow本身所表示含義�����。Tensor表示張量���,是TensorFlow的核心數(shù)據(jù)單位,其本質(zhì)是一個任意維的數(shù)組��。Flow(流)表示基于數(shù)據(jù)流圖的計算�����,構(gòu)建執(zhí)行流圖是TensorFlow開發(fā)過程中的重點。它表示的是張量從流圖的一端流動到另一端計算過程����,正是這種基于流的架構(gòu)讓它具有了更高的靈活性。TensorFlow系統(tǒng)架構(gòu)如下圖所示
TensorFlow系統(tǒng)架構(gòu)
LSTM(LongShort-Term Memory)是傳統(tǒng)遞歸神經(jīng)網(wǎng)絡(luò)RNN(Recurrent Neural Networks)改良后的成果�,是一款長短期記憶網(wǎng)絡(luò)。它是由Ho?chreiter和Schmidhuber在1997年提出的��。相較于普通的RNN��,LSTM增加了一個記憶單元(cell)用于判斷信息有用與否�,解決了長序列訓(xùn)練過程中的梯度消失和梯度爆炸問題。這一改進(jìn)使得其能在更長的序列中有更好的表現(xiàn)���。
記憶單元的狀態(tài)(cellstate)是LSTM的關(guān)鍵���,為了保護和控制記憶單元的狀態(tài),一個記憶單元中被放置了三個控制門���,分別叫做輸入門�、遺忘門和輸出門。每個控制門由一個包含一個sigmoid函數(shù)的神經(jīng)網(wǎng)絡(luò)層和一個點乘操作組成�����。LSTM記憶單元的結(jié)構(gòu)圖如下圖所示��。圖中從左方的輸入
的一條貫穿示意圖頂部的水平線即為記憶單元的狀態(tài)�。遺忘門、輸入門��、輸出門的神經(jīng)網(wǎng)絡(luò)層均用
層則分別對應(yīng)記憶單元的輸入與輸出,其中第一個
關(guān)于輸入門����、遺忘門和輸出門的詳細(xì)介紹如下:
一個信息進(jìn)入LSTM的網(wǎng)絡(luò)當(dāng)中,只有符合算法認(rèn)證的信息才可以不被遺忘�。完成是否遺忘判斷的是包含
來決定上一時刻的單元狀態(tài)有多少可以被保留到當(dāng)前時刻�。
輸入門通過sigmoid來決定當(dāng)前時刻網(wǎng)絡(luò)的輸入
���,用來更新記憶單元狀態(tài),如下式所示
代入下式�����,這樣即可將當(dāng)前單元狀態(tài)
���。它首先通過sigmoid層來得到一個初始輸出
值推到-1和1之間����。最終將sigmoid層和
層的輸出相乘,以此實現(xiàn)對單元狀態(tài)
下面首先從簡單的案例來進(jìn)行分析����,這里只考慮單變量時間序列預(yù)測。注意�,下面代碼并非完整代碼展示,主要是對程序主要步驟進(jìn)行詳細(xì)說明�。完整代碼請見文末。此外�,這里默認(rèn)大家都已經(jīng)搭建和配置好了Python環(huán)境下TensorFlow����。
利用函數(shù)加隨機噪聲的方法生成一個較為復(fù)雜的實驗用時間序列數(shù)據(jù)��。x對應(yīng)時間序列的“觀察的時間點”,y對應(yīng)時間序列的“觀察到的值”���。然后將入x和y合并成data(Python中的字典)完成數(shù)據(jù)讀入�。再使用NumpyReader使之轉(zhuǎn)換為Tensor形式���,接著用tf.contrib.timeseries.RandomWindowInputFn將其變?yōu)閎atch訓(xùn)練數(shù)據(jù)�。這是一個有4個隨機序列的訓(xùn)練數(shù)據(jù)batch�,且每個序列長度為100。具體實現(xiàn)代碼如下:
noise= np.random.uniform(-0.2, 0.2, 1000) #隨機噪聲
y= np.sin(np.pi * x / 50 ) + np.cos(np.pi * x / 50) + np.sin(np.pi * x/ 25) + noise
tf.contrib.timeseries.TrainEvalFeatures.TIMES:x, #TFTS 讀入x
tf.contrib.timeseries.TrainEvalFeatures.VALUES:y, #TFTS 讀入y
reader= NumpyReader(data)
train_input_fn= tf.contrib.timeseries.RandomWindowInputFn(
reader, batch_size=4,window_size=100)
利用TFTS提供的LSTM模型����,其中由于是單變量時間序列,每個觀測點只對應(yīng)一個數(shù)值所以需要令num_features=1�����。num_units=128表示使用隱層為128大小的LSTM模型。在優(yōu)化器的選擇上���,選用了實現(xiàn)了Adam算法的優(yōu)化器tf.train.AdamOptimizer��,能基于訓(xùn)練數(shù)據(jù)迭代地更新神經(jīng)網(wǎng)絡(luò)權(quán)重�。
estimator= ts_estimators.TimeSeriesRegressor(model=_LSTMModel(num_features=1,num_units=128),
optimizer=tf.train.AdamOptimizer(0.001))
Estimator是一種可極大地簡化機器學(xué)習(xí)編程的高階TensorFlowAPI�,借助預(yù)創(chuàng)建的Estimator可以快速實現(xiàn)訓(xùn)練集的訓(xùn)練����、評估和預(yù)測。實現(xiàn)代碼如下:
estimator.train(input_fn=train_input_fn,steps=2000) #訓(xùn)練
evaluation_input_fn= tf.contrib.timeseries.WholeDatasetInputFn(reader)
evaluation= estimator.evaluate(input_fn=evaluation_input_fn, steps=1) #評估
(predictions,)= tuple(estimator.predict(
input_fn=tf.contrib.timeseries.predict_continuation_input_fn(
定義變量分別記錄實驗生成的時間序列數(shù)據(jù)����,預(yù)測的時間序列數(shù)據(jù)以及向后預(yù)測的實驗數(shù)據(jù)并繪圖保存。實現(xiàn)代碼如下:
observed_times= evaluation["times"][0] #記錄實驗用時間序列數(shù)據(jù)的時間
observed= evaluation["observed"][0, :, :] #記錄實驗用時間序列數(shù)據(jù)的值
evaluated_times= evaluation["times"][0] #記錄預(yù)測值對應(yīng)的時間
evaluated= evaluation["mean"][0] #記錄預(yù)測值
predicted_times= predictions['times'] #記錄向后預(yù)測的預(yù)測值對應(yīng)的時間
predicted= predictions["mean"] #記錄向后預(yù)測的預(yù)測值
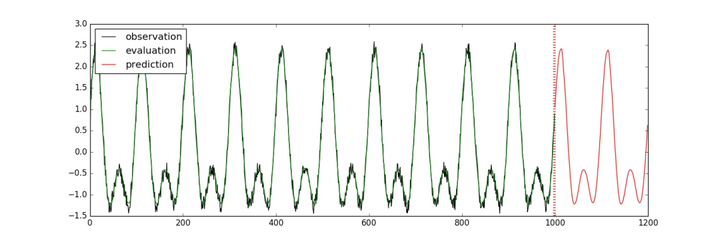
plt.figure(figsize=(15,5)) #定義圖片
plt.axvline(999,linestyle="dotted", linewidth=4, color='r') #畫豎直分割線
observed_lines= plt.plot(observed_times, observed, label="observation",color="k") #定義線條
evaluated_lines= plt.plot(evaluated_times, evaluated, label="evaluation",color="g")
predicted_lines= plt.plot(predicted_times, predicted, label="prediction",color="r")
plt.legend(handles=[observed_lines[0],evaluated_lines[0], predicted_lines[0]],
plt.savefig('predict_result.jpg') #保存圖片
運行后���,畫出的圖像會保存成“predict_result.jpg”文件�����?�?梢缘玫饺缦聢D結(jié)果:
案例1中只是針對單一變量時間序列進(jìn)行了預(yù)測���,這里我們通過改變變量數(shù)來進(jìn)行多變量時間序列預(yù)測。依然要注意��,下面的代碼并非完整代碼展示����,主要是對程序主要步驟進(jìn)行詳細(xì)說明。完整代碼請見文末��。
所謂多變量時間序列�����,就是指在每個時間點上的觀測量有多個值�。多變量時間序列預(yù)測與單變量時間序列預(yù)測的不同之處在于單變量預(yù)測每個時間點上的觀測值只有一個,而多變量預(yù)測則有多個�。與生成實驗用時間序列數(shù)據(jù)不同,使用TFTS讀入CSV文件首先需要引入文件并且需要通過column_names參數(shù)告訴TFTS文件中那些是時間����,那些是觀測量。具體實現(xiàn)代碼如下:
csv_file_name= path.join("./data/multivariate_periods.csv")
reader =tf.contrib.timeseries.CSVReader(
column_names=((tf.contrib.timeseries.TrainEvalFeatures.TIMES,) #觀測時間
+(tf.contrib.timeseries.TrainEvalFeatures.VALUES,) * 5)) #觀測量
train_input_fn= tf.contrib.timeseries.RandomWindowInputFn(
reader, batch_size=4,window_size=32)
唯一區(qū)別于單變量時間序列預(yù)測的在于��,由于每個觀測時間對應(yīng)的觀測量有5個,num_features=5����。
estimator= ts_estimators.TimeSeriesRegressor(
model=_LSTMModel(num_features=5,num_units=128),
optimizer=tf.train.AdamOptimizer(0.001))
第三步訓(xùn)練、驗證����、預(yù)測以及繪圖
與單變量原理及代碼相同,這里就不再重復(fù)����。同樣,最后的運行結(jié)果會保存成“predict_result.jpg”文件�����,如下圖所示:
通過上述兩個案例分析可以發(fā)現(xiàn)��,在TensorFlow框架下引入LSTM模型會很好的對單變量時間序列和多變量時間序列進(jìn)行預(yù)測��,預(yù)測線條與實際線條接近重合����,預(yù)測效果非常直觀,見上面圖中運行結(jié)果����。
本文首先介紹了TensorFlow深度學(xué)習(xí)框架和LSTM網(wǎng)絡(luò)的基本概念。通過單變量時間序列預(yù)測和多變量時間序列預(yù)測兩個案例�,詳細(xì)地用實例代碼介紹了TensorFlow引入的LSTM模型。從兩次預(yù)測結(jié)果可以發(fā)現(xiàn)�,預(yù)測均取得了較好的效果。該模型可用于解決實際工作中的一些時間序列預(yù)測問題��,具有一定的實際意義����。

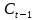
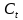
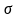
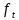
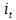
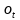
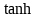
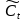
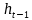
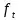
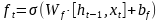
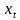
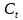
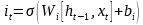
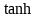
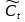
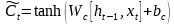
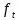
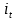
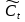
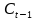
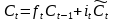
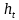
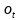
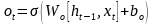
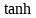


 京公網(wǎng)安備 11010802020714號
京ICP備2020047077號-2
京公網(wǎng)安備 11010802020714號
京ICP備2020047077號-2



 手機端官網(wǎng)
手機端官網(wǎng)