摘要:
本文對KNN算法做一個通俗易懂的介紹,值得收藏���!
古語云:“近水樓臺先得月”���,意思是臨近在水邊的樓臺就能優(yōu)先得到月亮的光芒,也比喻由于接近某些人或事物而搶先得到某種利益或便利���。還有一句類似的話:“遠(yuǎn)親不如近鄰”���,說的是人在有需要時,鄰居比遠(yuǎn)處的親戚更加能獲得支持和幫助��。在人工智能領(lǐng)域�,有一種算法,非常貼近上述的形象比喻��,這就是KNN算法����,即K最近鄰算法(K-NearestNeighbors,簡稱KNN)���,它是一個比較簡單的機(jī)器學(xué)習(xí)算法��,也是一個理論上比較成熟的���、運(yùn)用基于樣本估計的最大后驗(yàn)概率規(guī)則的判別方法�。本文對KNN算法做一個通俗易懂的介紹�,并通過python進(jìn)行編碼示范,讓讀者朋友對該算法有較好的理解����。
K最近鄰算法的比較貼近的一個比喻場景是:一個牧場里���,放養(yǎng)著許多牛和羊���,它們交叉聚集生活在一起,有時某只動物自己都可能分不清自己是牛還是羊����。按照K最近鄰算法,它判別自己是?�;蛘哐虻囊罁?jù)是——“我”周邊離“我”最近的類別(?�;蛘哐颍?,且在一定范圍內(nèi)是數(shù)量最多的類別,那“我”就是這個類別�。歸結(jié)到K最近鄰算法中,就是在一個數(shù)據(jù)集中�,新的數(shù)據(jù)點(diǎn)離哪一類最近且一定范圍內(nèi)最多,就和這一類屬于同一類�����。
其中�,這個一定范圍就是鄰居們(Neighbors)的數(shù)量,也就是K最近鄰算法的“K”這個字母代表的數(shù)量(最近鄰的個數(shù))���。在人工智能領(lǐng)域��,大家所熟知的scikit-learn庫中���,K最近鄰算法的K值可以通過n_neighbors參數(shù)來調(diào)節(jié)的,默認(rèn)值是5����。
“近水樓臺”——KNN預(yù)測實(shí)戰(zhàn)
“近水樓臺先得月”可以很好地詮釋KNN算法,下面我們進(jìn)行一個KNN算法的實(shí)際應(yīng)用�����,以方便讀者更好地理解KNN算法。
當(dāng)今每屆大學(xué)生在畢業(yè)前一年都非常關(guān)注研究生考試����,能進(jìn)入碩士級別進(jìn)一步深造,也是大多數(shù)學(xué)生所渴望的���,本文將模擬某年部分碩士研究生的入學(xué)考試數(shù)據(jù)集�����,通過python編程演練一個KNN算法機(jī)器學(xué)習(xí)的建模��、訓(xùn)練�、預(yù)測過程�,展示KNN算法的效果。
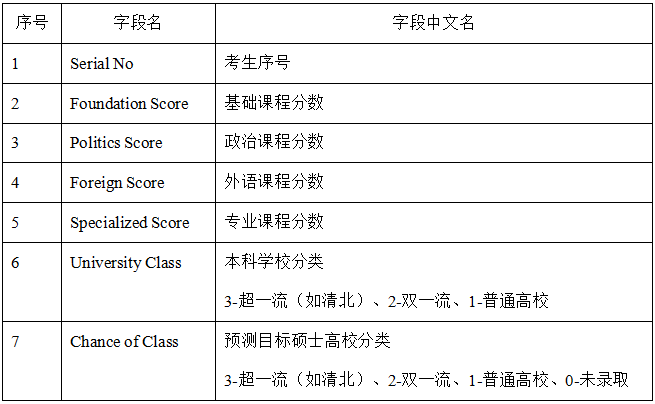
其中��,2�、3�����、4、5����,分別是研究生入學(xué)考試的基礎(chǔ)課程�����、政治課程��、外語課程��、專業(yè)課程的分?jǐn)?shù)���。
6是考試學(xué)生的本科學(xué)校分類����,分類粗略的分為三級:3-超一流(如清北)���、2-雙一流�、1-普通高校�����。
7是考試學(xué)生的目標(biāo)碩士高校學(xué)校的分類,分類粗略的分為四級:3-超一流(如清北)����、2-雙一流、1-普通高校���、0-表示未被錄取����。
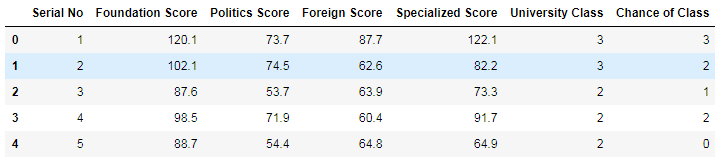
二��、導(dǎo)入和查看��、準(zhǔn)備數(shù)據(jù)集
#使用pandas加載碩士研究生入學(xué)成績信息數(shù)據(jù)集
data= pd.read_csv('Graduate_Admission.csv')
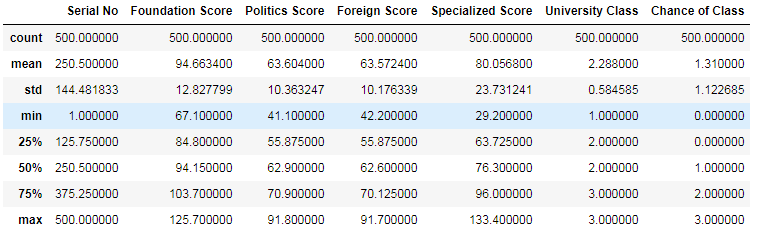
#查看數(shù)據(jù)特征的統(tǒng)計信息
上表說明:這個數(shù)據(jù)集總共有500條記錄����,其中基礎(chǔ)課程的最高分和最低分是125.7和67.1,政治課程的最高分和最低分是91.8和41.1,外語課的最高分和最低分是91.7和42.2��,專業(yè)課程的最高分和最低分是133.4和29.2����。
下面的代碼針對數(shù)據(jù)集做預(yù)處理:
data.drop(['SerialNo'], axis = 1, inplace = True)
#把去掉預(yù)測目標(biāo)Chanceof Class后的數(shù)據(jù)集作為訓(xùn)練數(shù)據(jù)集X
X= data.drop(['Chance of Class'], axis = 1)
y= data['Chance of Class'].values
三、生成訓(xùn)練集和測試集��、使用KNN算法建模并評估模型分?jǐn)?shù)
fromsklearn.model_selection import train_test_split
#將數(shù)據(jù)集拆分為訓(xùn)練數(shù)據(jù)集和測試數(shù)據(jù)集
X_train,X_test, y_train, y_test = train_test_split(X, y, random_state=0)
fromsklearn.neighbors import KNeighborsClassifier
Clf_KNN= KNeighborsClassifier()
#用模型對數(shù)據(jù)進(jìn)行擬合
Clf_KNN.fit(X_train,y_train)
KNeighborsClassifier(algorithm='auto',leaf_size=30, metric='minkowski', metric_params=None, n_jobs=None,n_neighbors=5, p=2, weights='uniform')
print('驗(yàn)證數(shù)據(jù)集得分:{:.2f}'.format(Clf_KNN.score(X_test,y_test)))
print('訓(xùn)練數(shù)據(jù)集得分:{:.2f}'.format(Clf_KNN.score(X_train,y_train)))
驗(yàn)證數(shù)據(jù)集得分:0.81
訓(xùn)練數(shù)據(jù)集得分:0.87
可以看出模型的訓(xùn)練集和驗(yàn)證集的評估分值都在0.80分以上�,模型訓(xùn)練的效果還算不錯。
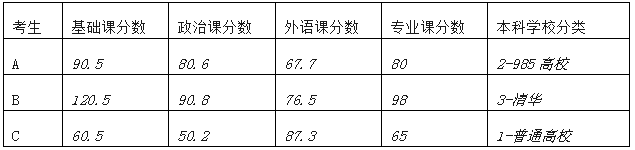
現(xiàn)在有A�、B、C三位同學(xué)都進(jìn)行了研究生入學(xué)模擬考試�����,他們的成績和本科學(xué)校分別是:
我們可以利用上面步驟建立的KNN模型來預(yù)測一下����,看看他們目前的考試成績能夠進(jìn)入研究生高校的類別是哪些:是成功登上清華北大的超一流神圣殿堂或者普通高校,還是遺憾地鎩羽而歸����。經(jīng)過這樣的預(yù)測后�,相信他們也會有一定的信心或者更加強(qiáng)化自身的學(xué)習(xí)力度���,力爭能考入心儀的理想學(xué)校�。
下面使用python代碼利用前面已經(jīng)建好的KNN模型�����,對三位同學(xué)的研究生成績的入學(xué)結(jié)果進(jìn)行預(yù)測:
#輸入A同學(xué)的考試成績和學(xué)校分類數(shù)據(jù)
X_A= np.array([[90.5, 80.6, 67.7, 80, 2]])
#使用.KNN模型對A同學(xué)的入學(xué)可能分類進(jìn)行預(yù)測
pred_A= Clf_KNN.predict(X_A)
#輸入B同學(xué)的考試成績和學(xué)校分類數(shù)據(jù)
X_B= np.array([[120.5, 90.8, 76.5, 98, 3]])
#使用.KNN模型對B同學(xué)的入學(xué)可能分類進(jìn)行預(yù)測
pred_B= Clf_KNN.predict(X_B)
#輸入C同學(xué)的考試成績和學(xué)校分類數(shù)據(jù)
X_C= np.array([[60.5, 50.2, 87.3, 65, 1]])
#使用.KNN模型對C同學(xué)的入學(xué)可能分類進(jìn)行預(yù)測
pred_C= Clf_KNN.predict(X_C)
print("K最近鄰算法模型預(yù)測分類結(jié)果如下:")
print("A同學(xué)的分類結(jié)果:{}".format(pred_A))
print("B同學(xué)的分類結(jié)果:{}".format(pred_B))
print("C同學(xué)的分類結(jié)果:{}".format(pred_C))
K最近鄰算法模型預(yù)測分類結(jié)果如下:
以上結(jié)果說明��,如果按他們的模擬考試成績����,A同學(xué)分類預(yù)測結(jié)果為“1-普通高校”�,即KNN模型預(yù)測他能夠考入一般的普通高校的研究生;B同學(xué)分類預(yù)測結(jié)果為“3-超一流高校(如清北)”��,即KNN模型預(yù)測他能進(jìn)入清北超一流殿堂�,值得慶祝;C同學(xué)分類預(yù)測結(jié)果為“0-未被錄取”�����,很遺憾,KNN模型預(yù)測他成績不理想�,無法考上研究生。
通過這個數(shù)據(jù)集和例子可以得出一定的推論:考試成績好且在超一流高校讀本科的學(xué)生��,更容易被超一流的高校(如清北)的碩士學(xué)位錄取����,超一流高校(如清北)的學(xué)生可以說是“近水樓臺”,比其他學(xué)生更容易“先得月”���,也比較好地詮釋了KNN算法的工作原理����。
K最近鄰算法(KNN)可以說是一個非常經(jīng)典�、原理十分容易理解的算法�。本文利用KNN算法解決了一個研究生入學(xué)考試成績的被錄取高校的分類預(yù)測問題,其實(shí)��,K最近算法不僅能夠進(jìn)行分類預(yù)測���,也可以用于回歸����,原理和其用于分類是相同的。
另外��,利用KNN算法進(jìn)行機(jī)器學(xué)習(xí)的過程中����,對K值(Neighbors的數(shù)量)的選擇會對算法的結(jié)果產(chǎn)生重大影響。K值較小意味著只有與輸入實(shí)例較近的訓(xùn)練實(shí)例才會對預(yù)測結(jié)果起作用��,但容易發(fā)生過擬合����;如果K值較大,優(yōu)點(diǎn)是可以減少學(xué)習(xí)的估計誤差�,但缺點(diǎn)是學(xué)習(xí)的近似誤差增大。有興趣的讀者朋友可以在上述Python代碼中修改K值����,看看是否能得到不同的預(yù)測結(jié)果。
 京公網(wǎng)安備 11010802020714號
京ICP備2020047077號-2
京公網(wǎng)安備 11010802020714號
京ICP備2020047077號-2



 手機(jī)端官網(wǎng)
手機(jī)端官網(wǎng)