摘要:
五款必備高效Python數(shù)據(jù)分析庫(kù),你知道幾個(gè)�����?
在大數(shù)據(jù)時(shí)代�,數(shù)據(jù)思維已開(kāi)始深刻變革各行各業(yè),從我們的電商消費(fèi)信息���、運(yùn)動(dòng)軌跡�����、社交數(shù)據(jù)���、產(chǎn)品使用習(xí)慣,到企業(yè)的調(diào)研����、設(shè)計(jì)、產(chǎn)品��、運(yùn)營(yíng)、營(yíng)銷(xiāo)�����,再到交通�、金融、生產(chǎn)制造����、公共服務(wù)。而由于Python在數(shù)據(jù)獲取���、數(shù)據(jù)處理���、數(shù)據(jù)分析、數(shù)據(jù)挖掘����、數(shù)據(jù)可視化、機(jī)器學(xué)習(xí)��、人工智能等方面有著非常多成熟的庫(kù)以及活躍的社區(qū)�,構(gòu)成數(shù)據(jù)科學(xué)領(lǐng)域最為完整且完善的生態(tài)。
尤其是在NLP(自然語(yǔ)言處理)項(xiàng)目中�,用Python來(lái)處理數(shù)據(jù)也就變得更加廣泛了����。下面將詳細(xì)地介紹五款必備的高效Python數(shù)據(jù)分析庫(kù)���。這會(huì)對(duì)我們編寫(xiě)高級(jí)復(fù)雜的程序幫助很大。但不用擔(dān)心�,你不需要有任何技術(shù)基礎(chǔ)就可上手這些庫(kù)。
一.Numerizer庫(kù)����,文本數(shù)字的分析轉(zhuǎn)換
Numerizer是一個(gè)將自然語(yǔ)言中文本數(shù)字快速轉(zhuǎn)換為整數(shù)型(int)和浮點(diǎn)型(float)數(shù)字的Python模塊或庫(kù)。它是一個(gè)開(kāi)源的GitHub項(xiàng)目(https://github.com/jaidevd/numerizer)���。特別說(shuō)明����,為了方便演示該庫(kù)的使用�。這里推薦使用Anaconda,它是一個(gè)開(kāi)源的Python發(fā)行版本,其包含了conda����、Python等180多個(gè)科學(xué)包及其依賴(lài)項(xiàng),非常適合初學(xué)者��。
打開(kāi)Anaconda的終端,輸入如下語(yǔ)句進(jìn)行Numerizer庫(kù)的安裝����。
2.Numerizer庫(kù)實(shí)例演示
安裝完成后,我們可以運(yùn)行Anaconda內(nèi)置的spyder��,并輸入以下語(yǔ)句
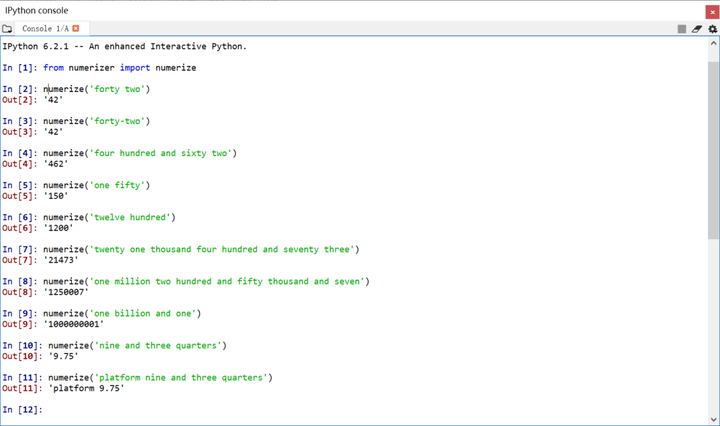
fromnumerizer import numerize
numerize('fourhundred and sixty two')
numerize('twelvehundred')
numerize('twentyone thousand four hundred and seventy three')
numerize('onemillion two hundred and fifty thousand and seven')
numerize('onebillion and one')
numerize('nineand three quarters')
numerize('platformnine and three quarters')
程序運(yùn)行結(jié)果如下圖所示�,可以很清楚地發(fā)現(xiàn),英文文字?jǐn)?shù)字被準(zhǔn)備轉(zhuǎn)換成了相應(yīng)的數(shù)字��。
二.Missingo庫(kù)�,丟失值可視化分析
在現(xiàn)實(shí)世界的數(shù)據(jù)集中發(fā)現(xiàn)丟失值是很普遍的。每次處理數(shù)據(jù)時(shí)��,缺失值是必須要考慮的問(wèn)題��。但是手工查看每個(gè)變量的缺失值是非常麻煩的一件事情��。數(shù)據(jù)分析之前首先要保證數(shù)據(jù)集的質(zhì)量�����。Missingo就是一個(gè)可視化丟失值的庫(kù)��。它提供了一個(gè)靈活且易于使用的缺失數(shù)據(jù)可視化和實(shí)用程序的小工具集�����,使您可以快速直觀地總結(jié)數(shù)據(jù)集的完整性。(該庫(kù)的GitHub地址:https://github.com/ResidentMario/missingno)
這里同樣是使用Anaconda���,打開(kāi)Anaconda的終端后�����,輸入如下語(yǔ)句進(jìn)行Missingo庫(kù)的安裝
2. Missingo庫(kù)實(shí)例演示
下面的樣例數(shù)據(jù)使用NYPD Motor VehicleCollisions Dataset 數(shù)據(jù)集.運(yùn)行下面語(yǔ)句即可獲得數(shù)據(jù)
quiltinstall ResidentMario/missingno_data
之后,加載數(shù)據(jù)到內(nèi)存�����,輸入以下語(yǔ)句
fromquilt.data.ResidentMario import missingno_data
collisions= missingno_data.nyc_collision_factors()
collisions= collisions.replace("nan", np.nan)
在Missingo庫(kù)中�,有幾個(gè)主要函數(shù)以不同方式的可視化展示數(shù)據(jù)集數(shù)據(jù)缺失情況。其中���,Matrix是使用最多的函數(shù)�,能快速直觀地看到數(shù)據(jù)集的完整性情況�����。輸入以下語(yǔ)句:
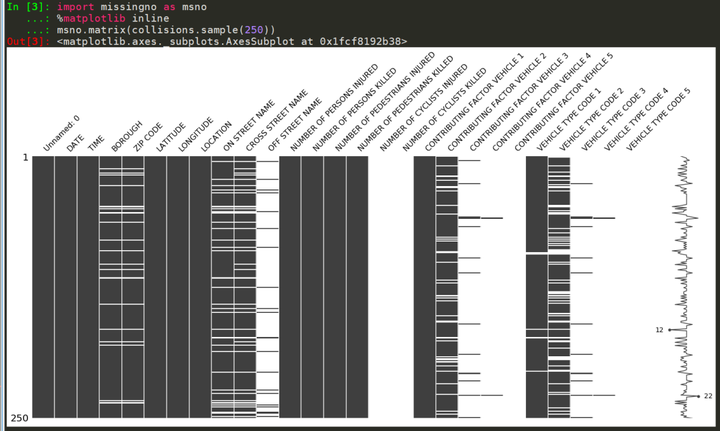
msno.matrix(collisions.sample(250))
程序運(yùn)行后��,矩陣顯示的結(jié)果如下。圖中右邊顯示的迷你圖總結(jié)了數(shù)據(jù)集的總的完整性分布�����,并標(biāo)出了完整性最大和最小的點(diǎn)���。
特別說(shuō)明���,這里也可以通過(guò)figsize指定輸出圖像大小,例如下面語(yǔ)句:msno.matrix(collisions.sample(250),figsize=(12,5))
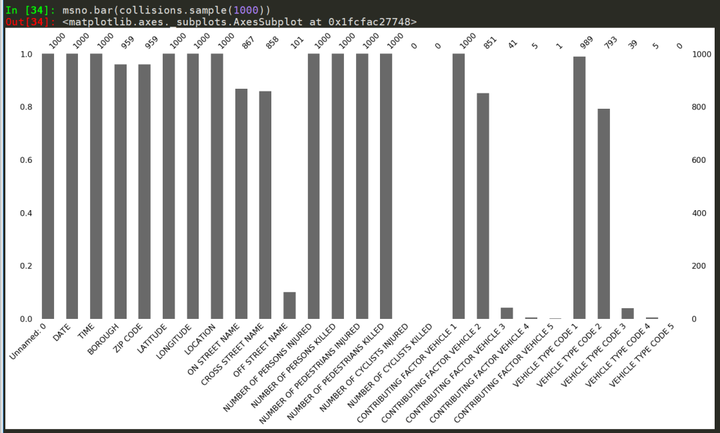
此外�����,msno.bar函數(shù)也是一個(gè)非常有用的函數(shù)�����,可以簡(jiǎn)單地展示無(wú)效數(shù)據(jù)的條形圖��。
msno.bar(collisions.sample(1000))
程序運(yùn)行后���,顯示的數(shù)據(jù)條形圖:
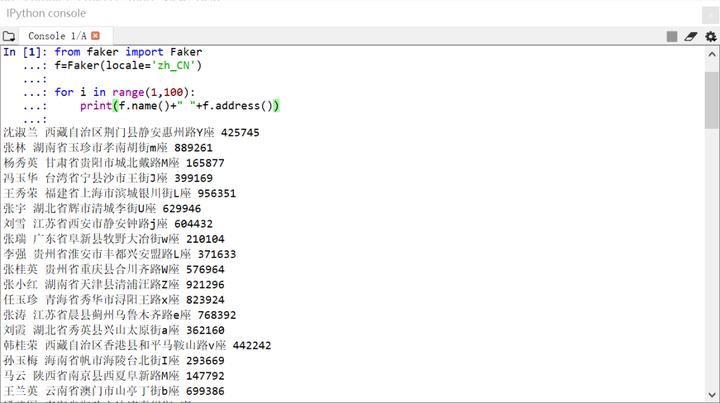
三.Faker庫(kù)�,虛擬測(cè)試數(shù)據(jù)生成器
在軟件需求�、開(kāi)發(fā)���、測(cè)試過(guò)程中,我們可能會(huì)遇到需要生成一些測(cè)試數(shù)據(jù)或在分析中使用一些虛擬數(shù)據(jù)的情況�。針對(duì)這種情況,我們一般要么使用已有的系統(tǒng)數(shù)據(jù)��,要么需要手動(dòng)制造一些數(shù)據(jù)��。但由于現(xiàn)在的業(yè)務(wù)系統(tǒng)數(shù)據(jù)多種多樣���,千變?nèi)f化����。在手動(dòng)制造數(shù)據(jù)的過(guò)程中����,可能需要花費(fèi)大量精力和工作量�,此項(xiàng)工作既繁復(fù)又容易出錯(cuò),而且�,部分?jǐn)?shù)據(jù)的手造工作無(wú)法保障:比如UUID類(lèi)數(shù)據(jù)、MD5���、SHA加密類(lèi)數(shù)據(jù)等����。
Faker是一個(gè)Python庫(kù),開(kāi)源的GITHUB項(xiàng)目(https://github.com/joke2k/faker)�,主要用來(lái)創(chuàng)建偽數(shù)據(jù),使用Faker包�,無(wú)需再手動(dòng)生成或者手寫(xiě)隨機(jī)數(shù)來(lái)生成數(shù)據(jù),只需要調(diào)用Faker提供的方法�����,即可完成數(shù)據(jù)的快速生成�����。
特別說(shuō)明,關(guān)于初始化參數(shù)locale:為生成數(shù)據(jù)的文化選項(xiàng)��,默認(rèn)為英文(en_US)�。如果要生成相對(duì)應(yīng)的中文隨機(jī)信息(比如:名字,地址�����,郵編,城市���,省份等)�����,需使用zh_CN值�����。
之后�����,輸入下面語(yǔ)句�,將隨機(jī)生成假的中文名字和地址�,非常簡(jiǎn)單易用�。
print(f.name()+" "+f.address())
四.Emot庫(kù),表情符號(hào)數(shù)據(jù)分析
在情感數(shù)據(jù)分析方面�����,收集和分析有關(guān)表情符號(hào)的數(shù)據(jù)可以提供非常有用的信息�。而表情符號(hào)是一種小到可以插入到表達(dá)情感或想法的文本中的圖像����。它僅由使用鍵盤(pán)字符(如字母��、數(shù)字和標(biāo)點(diǎn)符號(hào))組成��。
Emot庫(kù)也是一個(gè)開(kāi)源Github項(xiàng)目(https://github.com/NeelShah18/emot)���,可以幫助我們把表情符號(hào)emojis和emoticons轉(zhuǎn)換成單詞�。它有一個(gè)很全面的表情符號(hào)與相應(yīng)單詞映射的集合����。
 京公網(wǎng)安備 11010802020714號(hào)
京ICP備2020047077號(hào)-2
京公網(wǎng)安備 11010802020714號(hào)
京ICP備2020047077號(hào)-2



 手機(jī)端官網(wǎng)
手機(jī)端官網(wǎng)